Research and publish the best content.
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account
Already have an account: Login

Complex Insight - Understanding our world
12.2K views |
+0 today


A few things the Symbol Research team are reading. Complex Insight is curated by Phillip Trotter (www.linkedin.com/in/phillip-trotter) from Symbol Research
Curated by
Phillip Trotter
 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
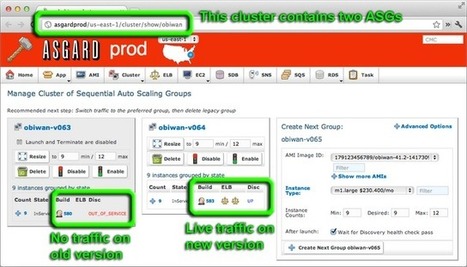
For the past several years Netflix developers have been using self-service tools to build and deploy hundreds of applications and services to the Amazon cloud. One of those tools is Asgard, a web interface for application deployments and cloud management. 

Over the last year we have been experimenting with different data processing platforms including Hadoop, HPCC, several graph databases and NOSQL databases. WE selected a hybrid of STORM and HPCC since combined they are a great match to our processing needs, both have permissive open source licenses and good resources.
Many Big data articles fail to mention that Big Data applications have varying requirements and the different available toolsets suit different applications and circumstances. One of the reasons we went with HPCC is we have good C++ skills on our team, we liked the ECL language and systems architecture. We could see how pur target workflows would map (it helps that the Lexis Nexis team have addressed similar areas int he past and it shows in the product) and we could easily see how to integrate the HPCC functionality with our C++, Java and Python tools.
If we were a pure java only house then HADOOP,CASCADE and HIVE would be a much better match for non real time procesing. Tools like Storm are better architected for real time event processing (hence our hybrid choice). One of the essential lessons and take aways is that each domain and circumstance has different requirements. You have to play with the technologies, test them against workflows and see what works for your problem domain, performance requirements and team skills. For evaluating HPCC a great resource is Arjuna's blog. You will find worked examples discussion of trade offs and approaches and a lot of good information. If you are interested in learning about a great Big Data platform - its a good place to start. Click on the image or the title to learn more.
|

What a difference a year can make! Last year Fujitsu was focused on its K-Computer. With 88,128 traditional Sparc CPUs–each with eight cores for 705,028 total, K-Computer was declared the world’s fastest supercomputer in the 2011 Top500 Supercomputer list. In 2012, however, the K-Computer lost out to IBM’s Sequoia, which boasted more than twice as many PowerPC cores –1.5 million. Despite its high speed, the K-Computer consumed almost twice as much power per floating-point operation (825 GFlop/kWatt) compared to supercomputers based on the Xeon Phi, which are rated almost three times higher (2499 GFlop/kWatt) by the Green500 List. In addition, the ability to add 60-cores at a time with a single PCIe card drastically cuts the cost of HPCs.
Phillip Trotter's insight:
Interesting to see how the Xeon Phi is getting adopted into HPC and the types of configurations that it will enable. Click on the image or title to learn more

If you (or are planning to) use HPCC for large scale data processing then Juan Negron has a great post on configuring an ubuntu cluster with HPCC using JuJu. He walks you through creating the JuJu charm and deplozing the cluster. if large scale data processing is your thing then its worth a read. Click on the image or title to learn more.
|







Good article on the differences between big data processing and HPC simulations. Worth reading to see where the two communities focus, worry about and can learn from one another.