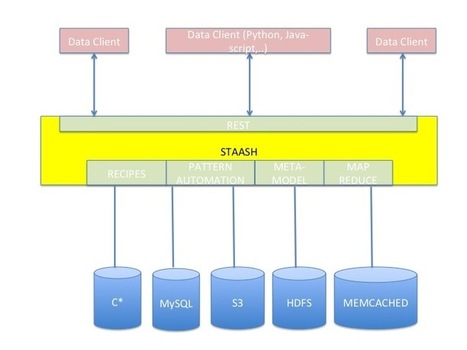
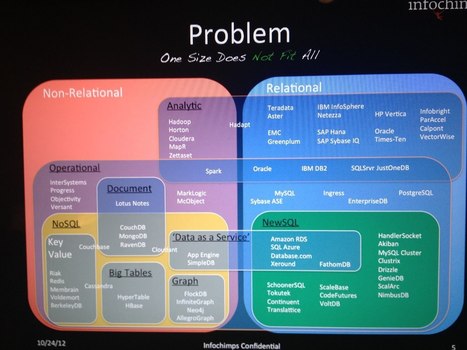
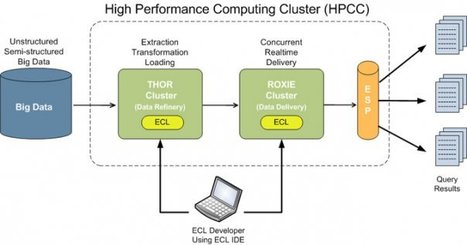
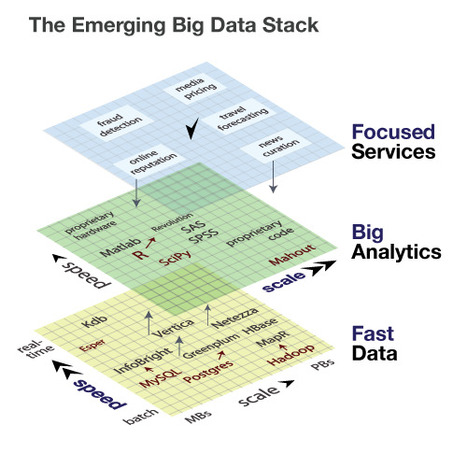
HPCC Systems, the division of LexisNexis Risk Solutions dedicated to big data, has released the open source code of its data-processing-and-delivery software it’s positioning as a better version of Hadoop. The High Performance Computing Cluster code is available on Github, and it marks the commencement of HPCC Systems’ quest to build a community of developers underneath Hadoop’s expansive shadow.
The HPCC architecture includes the Thor Data Refinery Cluster and the Roxy Rapid Data Delivery Cluster. As I explained when covering the HPCC Systems launch in June, “Thor — so named for its hammer-like approach to solving the problem — crunches, analyzes and indexes huge amounts of data a la Hadoop. Roxie, on the other hand, is more like a traditional relational database or database warehouse that even can serve transactions to a web front end.” Both tools leverage the company’s Enterprise Control Language, which Escalante describes as easier, faster and more efficient than Hadoop MapReduce.
Aside from the open source Community version, HPCC Systems also offers a paid Enterprise version of the HPCC product. The core code is the same, Escalante explained, with the major differences being additional enterprise-grade capabilities such as management tools and support and services.



 Your new post is loading...
Your new post is loading...